အိုင်စီတီ ဖွံ့ဖြိုးတိုးတက်မှုအတွက် Nature Language Processing (NLP)နဲ့ဆက်စပ်ပြီး လုပ်ကိုင်ဆောင်ရွက်နေတဲ့ မသင်ဇာဖြိုးကို မိတ်ဆက်ပေးချင်ပါတယ်။ သူမရဲ့ လုပ်ငန်းခွင်အတွေ့အကြုံကို အချိန်ကာလနဲ့တိုင်းတာမယ်ဆိုရင် သူမရဲ့လုပ်ငန်းခွင်အတွေ့အကြုံဟာ ၅ နှစ်ရှိပါပြီ။ လုပ်ငန်းခွင်ထဲမှာ ၅ နှစ်တာ ကာလကို ဖြတ်သန်းပြီး ရရှိလာတဲ့ သူမရဲ့အတွေ့အကြုံတွေက မနည်းပါဘူး။
မသင်ဇာဖြိုးဟာ စစ်ကိုင်းမြို့မှာ အခြေခံပညာအထက်တန်းကို အောင်မြင်ခဲ့တယ်။ ဖခင်ဖြစ်သူဟာ ဝန်ထမ်းတစ်ဦးဖြစ်တဲ့အတွက် ဖခင်တာဝန်ကျရာဒေသတွေမှာ လိုက်လံနေထိုင်ပြီး အခြေခံပညာကို သင်ယူခဲ့ရတယ်။ မန္တလေးကွန်ပျူတာတက္ကသိုလ်ကို တက်ခွင့်ရခဲ့တယ်။ B.C.Sc ကို အောင်မြင်ခဲ့တယ်။ Q (Qualify) တန်းကို တက်ရောက်ခွင့်ရခဲ့တယ်။ ဖခင်ဖြစ်သူဟာ လုပ်ငန်းတာဝန်နဲ့ ရန်ကုန်ကို ပြောင်းရွေ့လာ ရတဲ့အတွက် ရန်ကုန်ကွန်ပျူတာတက္ကသိုလ်မှာ Q တန်းကို ဆက်ပြီးတက်ရောက်ခဲ့တယ်။ ၂၀ဝ၄ ခုနှစ် နှစ်ကုန်ပိုင်းမှာ ကျောင်းပြီးခဲ့တယ်။
အသက်မွေးဝမ်းကျောင်း အစ
ကျောင်းပြီးတဲ့အချိန်မှာ အလုပ်စလုပ်ဖို့ တော်တော်ကြီးကို စိမ်းနေတယ်။ ကျောင်းတုန်းက တတိယနှစ်ကျမှ Virtual Basic 6 ကို စပြီး သင်တယ်။ အဲဒီအချိန်မှာ (ကျောင်း)အပြင်က .Net, Java ဖြစ်နေပြီ။ ကိုယ့်အနေနဲ့ လက်လှမ်းမီသလောက် လိုက်မယ်လို့ စဉ်းစားလိုက်တဲ့ အခါကျောင်းကပေးလိုက်တဲ့ ပညာရေးနောက်ခံအပြင် ပရောဖက်ရှင်နယ်ဖြစ်တဲ့ အောင်လက်မှတ်၊ လုပ်ငန်းအတွေ့အကြုံတွေရဖို့အတွက် Programmer လုပ်မလား၊ Developer လုပ်မလား ရွေးရတယ်။
ကျောင်းမှာ သင်ယူခဲ့ရတဲ့အပိုင်းက သီအိုရီတွေပါ။ Virtual Basic 6 က ကျောင်းမှာ နောက်ဆုံးသင်ခဲ့ရတဲ့ အပိုင်းပဲ။ Java ဆိုတာကို လုံးဝမသိဘူး။ စိမ်းနေတယ်။ ကွန်ပျူတာအ သင်းချုပ်နဲ့ ဂျပန်ပေါင်းဖွင့်တဲ့ Java သင်တန်းကို တက်ဖြစ်တယ်။ Professional နဲ့ Advance ဆိုပြီး Level နှစ်ခုရှိတယ်။ သင်တန်းမှာ ဂျပန်စာကိုလည်း သင်ပေးတယ်။
Professional Level တက်တဲ့အချိန်မှာ အခြေခံကနေ စပြီးတော့ သင်ပေးတယ်။ Java ကို စိတ်ဝင်စားခဲ့တယ်။ သင်တန်းကို အလုပ်လုပ်ဖို့ တက်ခဲ့တဲ့အတွက် အားစိုက်ပြီး သင်ယူဖြစ်ခဲ့တယ်။ အိုင်စီတီနယ်ပယ်ကို စတင်လေ့လာခဲ့တာက အဲဒီက စတာပါပဲ။ အိုင်စီတီနယ်ပယ်မှာ စပြီး အလုပ်ရှာတယ်ဆိုကတည်းက ဒါကိုပဲ လေ့လာချင်လို့။
ဘာသာစကားနဲ့ပတ်သက်ပြီး လုပ်ကိုင်ရမယ်
Myanmar NLP Lab ကို ရောက်လာတယ်။ ဆရာမကြီး(ဒေါက်တာ ဒေါ်မြင့်မြင့်သန်း)ကိုယ်တိုင် အင်တာဗျူးတယ်။ အဲဒီအချိန်တုန်းက NLP ဘာလဲလို့မေးရင် သေသေချာချာ မသိဘူး။ NLP ဆိုတာ ကျောင်းမှာပြောတဲ့ စကားနဲ့ပြောရင် ကျက်စာပါ။ အလုပ်ဝင်ခဲ့တဲ့သူ အများစုက လည်း မသိကြပါဘူး။ အလုပ်က မြန်မာစာနဲ့ပတ်သက်ပြီး လုပ်ရမယ်၊ စာတွေ ဖတ်ရမယ်လို့ ဆရာမကြီးက ပြောတယ်။ စိတ်ဝင်စား မိတယ်။ မိခင်ဘာသာစကားနဲ့ပတ်သက်ပြီး လုပ်ကိုင်ရမယ်ဆိုတော့ အသစ်အဆန်းလို့ သိလိုက်တယ်။ ကျွန်မအတွက် ပထမဆုံးအလုပ်ဖြစ်ခဲ့သလို အခုအချိန်အထိ ဆက်ပြီးလုပ်နေတဲ့ အလုပ်အကိုင်ပါပဲ။
လုပ်ငန်းခွင် အတွေ့အကြုံ အစပိုင်း
အလုပ်ဝင်တဲ့အချိန်က ၂၀ဝ၅ ခုနှစ် ၅ လပိုင်းလောက် ဖြစ်မယ်။ အလုပ်စလုပ်တဲ့အချိန်မှာ Myanmar 2 ကို မီခဲ့တယ်။ ကျွန်မအနေနဲ့ အလုပ်မဝင်ခင်ကတည်းက ယူနီကုတ်ရှိနေတယ်။ Myanmar1 က Unicode 4.1 နဲ့ ထွက်ပြီးသွားပြီ။ လက်ရှိအသုံးများနေတဲ့ ယူနီကုတ်စံကို အတိအကျ မလိုက်နာထားတဲ့ ဖောင့်ထက်စောပြီး Myanmar1 က ရှိနေခဲ့တယ်။
ယူနီကုတ်ကွန်ဆိုဒီယမ်မှာ မြန်မာဘာသာစကားပါဖို့အတွက် ဆရာဦးသိန်းဦးနဲ့ကိုဇော်ထွဋ်တို့ ယူနီကုတ်ကွန်ဆိုဒီယမ်ကို သွားပြီးတော့ ကြိုးပမ်းခဲ့ကြတယ်။ အဲဒီကို သွားဖို့အတွက် မြန်မာစာဆရာကြီးတွေနဲ့ မြန်မာစာအဖွဲ့က ဆရာကြီးတွေက မြန်မာစာနဲ့ပတ်သက်ပြီး တိုင်ပင်ကြတယ်။ အိုင်တီဖက်က ပညာရှင်တွေကလည်း ပူးပေါင်းတိုင်ပင်တယ်။ အဲဒီက ထွက်လာတဲ့ အကောင်းဆုံးရလာဒ်နဲ့ အမှန်ကန်ဆုံး နည်းလမ်းကို ယူပြီးတော့၊ ယူနီကုတ်ကွန်ဆိုဒီယမ်မှာ သွားပြီး ကြိုးပမ်းခဲ့ကြတယ်။ ဒီလိုကြိုးပမ်းမှုမျိုးကို ကိုယ်တိုင်မကြုံလိုက်ရပေမယ့် ဘယ်လောက်အထိ ခက်ခဲမယ်ဆိုတာ ချင့်ချိန်နိုင်တယ်။ တော်တော်ကို ခက်ခဲတဲ့ အလုပ်တစ်ခုပဲ။
စံသတ်မှတ်ချက်တစ်ခု ဖြစ်ဖို့
တစ်ချို့ ကိစ္စတွေမှာ လူအများစု အသုံးပြုနေလို့ စံအဖြစ် သတ်မှတ်လိုက်တာတွေ ရှိပါတယ်။ အများလက်ခံလို့ ဖြစ်သွားတဲ့ စံတစ်ခုပါ။ ဒါပေမယ့် နည်းပညာကိစ္စတွေမှာ အများက အသုံးပြုတိုင်း စံသတ်မှတ်ချက် ဖြစ်ပါတယ်လို့ လုပ်လို့မရနိုင်ဘူး။ ယူနီကုတ်ကွန်ဆိုဒီယမ်ဆိုတာ က Non Profit Organization (NPO) တစ်ခုဖြစ်တယ်။ အစိုးရမဟုတ်တဲ့ အဖွဲ့အစည်းတစ်ခုလည်း ဖြစ်တယ်။ သူတို့လုပ်တဲ့ လုပ်ငန်းတွေက ငွေကြေးအတွက် အကျိုးအမြတ်ရဖို့ မဟုတ်ဘူး။ နိုင်ငံတကာအဖွဲ့အစည်းဆိုတဲ့ အချက်တစ်ခုတည်းလည်း မဟုတ်ဘူး။ နိုင်ငံတိုင်းက ကွန်ပျူတာတွေ၊ ကွန်ပျူတာနဲ့ဆက်စပ်တဲ့ပစ္စည်းတွေပေါ်မှာ ကိုယ့်ရဲ့မိခင်ဘာသာစကားနဲ့ အသုံးပြုနိုင်ဖို့ ကုတ်တွေကို စံသတ်မှတ်ပြီး ချပေးတယ်။ ချပေးတဲ့ ကုတ်တွေကလည်း ဘာသာစကားတစ်ခုနဲ့တစ်ခု လုံးဝတူလို့ မရဘူး။
မြန်မာမှာရှိနေတဲ့ U1000 ဟာ တစ်ခြားဘာသာစကားတစ်ခုပေါ်မှာ သွားရှိနေရင် နိုင်ငံတကာစံနှုန်းဆိုတာ လုံးဝမဖြစ်နိုင်ဘူး။ မြန်မာအတွက် က ကကြီးဆို U1000 ပဲ၊ ခခွေးဆို U1001 ပဲ။ ဘယ်ဘာသာစကားနဲ့မှ တူညီစရာမရှိဘူး။ မြန်မာစာမှာရှိတဲ့ ဘာသာစကား စည်းမျဉ်းစည်းကမ်း တွေ၊ ဘာသာစကားတည်ဆောက်ပုံတွေနဲ့ ညီတဲ့ သတ်မှတ်ချက်တစ်ခုကို သူတို့ဆီ အရင်တင်ပြရတယ်။ ဒီလိုတင်ပြမှ လက်ခံသင့် လက်မခံ သင့် ဆုံးဖြတ်တယ်။ ဆုံးဖြတ်တဲ့အခါမှာလည်း အဓိကကျတဲ့ အချက်သုံးချက် ရှိတယ်။
ယူနီကုတ်ဆိုတာ ဘယ် Platform ပေါ်မှာမှ မမူတည်ဘူး။ OS ပေါ်မှာ သုံးချင်သလား။ Java ပေါ်မှာ သုံးချင်သလား။ C# ပေါ်မှာ သုံးချင် သလား။ .net အပေါ်မှာ သုံးချင် သလား။ ဘယ်ပေါ်မှာမဆို အသုံးပြုနိုင်ရတယ်။ ဒုတိယအချက်အနေနဲ့ Application တိုင်မှာ အသုံးပြုနိုင်ရ တယ်။ တတိယအချက်အနေနဲ့ မြန်မာနိုင်ငံအတွင်းမှာပဲ သုံးနိုင်တယ်။ တစ်ခြားနိုင်ငံမှာ သုံးလို့ မရနိုင်ဘူးဆိုတာလည်း မဖြစ်ရဘူး။ မြန်မာ အတွက်စံနှုန်းက တစ်ခြားနိုင်ငံမှာရှိတဲ့ စံနှုန်းတွေနဲ့လည်း ကိုက်ညီမှ ယူနီကုတ်ကွန်ဆိုဒီယမ်က ချပေးတယ်။
မိခင်ဘာသာစကားနဲ့ ကွန်ပျူတာကို အသုံးပြုဖို့
ကွန်ပျူတာမှာ မိခင်ဘာသာစကားကို စာစီစာရိုက်တစ်ခုတည်းအတွက်ပဲ သုံးတယ်ဆိုရင် မှားတယ်။ ကွန်ပျူတာပေါ်မှာ မိခင်ဘာသာ စကားနဲ့သုံးလို့ရတဲ့ အစိတ်အပိုင်းတွေ အများကြီးပဲ။ တကယ့်ကိုမှ အများကြီး၊ မရေမတွက်နိုင်အောင်ပဲ။ စာစီစာရိုက်လေးတစ်ခု၊ ဝက်ဘ် ပေါ်မှာ မြန်မာစာ ဖတ်နိုင်ဖို့ တစ်ခုထဲအတွက်ဆိုရင် ယူနီကုတ်ဆိုတာ ဖြစ်လာစရာမရှိဘူး။ စာစီစာရိုက်တစ်ခုတည်းအတွက်ဆိုရင် NLP Lab ဆိုတာ ရှိဖို့ မလိုအပ်ဘူး။ ကိုယ့်ရဲ့ မိခင်ဘာသာစကားမှာ ဘာသာစကားရဲ့ သဘာဝတွေရှိတယ်။ သူ့သဘာဝအတိုင်း ကွန်ပျူတာမှာ အလုပ် လုပ် စေချင်တယ်။ ဥပမာ-အခုသုံးနေတဲ့ Laptop မှာ မြင်နေရတဲ့ အချိန်တွေ၊ ပြက္ခဒိန်တွေက အင်္ဂလိပ်ဘာသာစကားနဲ့ ဖြစ်နေတယ်။ (စားပွဲ ပေါ်တွင်ရှိနေသည့် Laptop ကို ဥပမာထား၍ ပြောဆိုခြင်း ဖြစ်သည်။)
အချိန်တွေ၊ ပြက္ခဒိန်တွေကို ကွန်ပျူတာမှာ ကြည့်လို့ရနိုင်ဖို့ မြန်မာက ဘယ်အုပ်စုမှာ ဝင်နေသလဲဆိုတဲ့ Setting လုပ် ပြီးတော့မှ ကိုယ့်ရဲ့အချိန် ကို သိနိုင်တယ်။ မြန်မာရဲ့အချိန်ကို ဘယ်လိုမှ မသိနိုင်ဘူး။ မြန်မာရဲ့အချိန်ကို One, Two ဆိုတာနဲ့ပဲ သိနိုင်တယ်။ မြန်မာဂဏန်း ၁ ၊ ၂ နဲ့ အချိန်ကို မသိနိုင်ဘူး။ Naturel Language Processing ဆိုတာ ကိုယ့်ရဲ့ မိခင်ဘာသာစကားရယ်၊ ကွန်ပျူတာပေါ်မှာ သုံးလို့ရတဲ့ Programming Language နဲ့ Machine Language နှစ်ခုပေါင်းပြီး Processing လုပ်တာဖြစ်တယ်။
ကိုယ့်ဘာသာစကားကို ဒေသခံတစ်ယောက်အနေနဲ့ ဘယ်လောက်အထိ သိပြီလဲ။ ကကြီးကနေ အ အထိ အက္ခရာ ဘယ်နှစ်လုံးရှိလဲလို့ မေး လိုက်ရင် မသိတဲ့သူတွေ အများကြီးပဲ။ ကွန်ပျူတာပေါ်မှာ စာစီစာရိုက်လုပ်ရုံ၊ ဒီဇိုင်းလုပ်ရုံပဲ မိခင်ဘာသာစကားကို သုံးလို့ရတယ်ဆိုတာ ထက်ပိုပြီး NLP ကို သိစေချင်တယ်။
အပြောင်းအလဲ မြန်ခြင်းမဟုတ်
ယူနီကုတ်နဲ့ပတ်သက်ပြီး ပြင်ဆင်မှုတွေမှာ ကန့်ကွက်တဲ့သူတွေ ရှိလာတယ်ဆိုရင် ကွန်ဆိုဒီယမ်က ဘယ်လိုလူမျိုးက ကန့်ကွက်တာလဲဆို တာကို ကြည့်တယ်။ ဥပမာ- ကန့်ကွက်တဲ့ သူက ဘာသာဗေဒပညာရှင်လား၊ စနစ်သမားလားဆိုတာကို ကြည့်ပြီးတော့မှ စဉ်းစားတယ်။ ကကြီးကနေ အ အထိ နေရာရဖို့၊ ရရစ်ဆိုတာ ဘာလဲ၊ ရပျင့်ဆိုတာ ဘာလဲသိဖို့ ခက်ခဲတယ်ဆိုတာ လုပ်တဲ့ သူတွေ လဲ သိတယ်။ စိတ်ဝင်တ စားနဲ့လိုက်နေတဲ့ သူတွေလည်း ဒီအပိုင်းကို သိတယ်။ ယူနီကုတ်ကွန်ဆိုဒီယမ်က Version တွေတစ်ခုပြီး တစ်ခုထုတ်တယ်ဆိုတာ အပြောင်း အလဲမြန်တာမဟုတ်ဘူး။ ဘာသာစကားတစ်ခုမှာ ပြဿနာတစ်ခုရှိနေတယ်ဆိုရင်(ကွန်ဆိုဒီယမ်)ကို အဆိုပြုလွှာတင်ရတယ်။ အဲဒီအချိန် တုန်းက မြန်မာဘာသာစကားအတွက်လည်း ပြဿနာရှိတယ်။ မြန်မာဖက်က အဆိုပြုလွှာ၊ အခြားဘာသာစကားတစ်ခုက အဆိုပြုလွှာတွေ အကုန်လုံးကို စုတယ်။ စုပြီးတော့မှာ အားလုံးနဲ့ကိုက်ညီတဲ့ ရလာဒ်တစ်ခုကို ထုတ်တယ်။ Version တစ်ခုအနေနဲ့ နာမည်တပ်တယ်။ ဒီလိုထုတ် နိုင်ဖို့ အချိန်ဆိုတာက တင်သွင်းလာတဲ့ အဆိုပြုလွှာတွေ အပေါ်မှာမူတည်ပြီး ခြောက်လလည်း ဖြစ်နိုင်တယ်။ တစ်နှစ်လည်း ဖြစ်နိုင်တယ်။ သုံးနှစ်လည်း ဖြစ်နိုင်တယ်။
ကျွန်မအနေနဲ့ Version 2 ကနေ Version 3 အပြောင်းအလဲ ကာလကို ကြုံခဲ့ရတယ်။ Version 2 နဲ့ Version 3 မှာ ဘာပြောင်းသွားသလဲဆိုတော့ Code Point တွေက အပြောင်းအလဲမရှိဘူး။ Version ပြောင်းပေးမယ့် မြန်မာစာဘက်မှာ အပြောင်းအလဲမဖြစ်ဘူး။ တစ်ခြားဘာသာစကား တစ်ခုမှာတော့ အပြောင်းအလဲ ဖြစ်နိုင်တယ်။ Font Developing အနေနဲ့ ပြောရရင် Myanmar2 မှာတုန်းက အောက်ကမြင့်တွေ၊ ဝစ္စလုံးနှစ်လုံး ပေါက်တွေ၊ အတပ်တွေ ထပ်သွားခဲ့ရင် မြင်နိုင်အောင် အစက်ကလေးတွေပါတဲ့ စက်ဝိုင်းလေးတွေ ထပ်ထည့်လိုက်တယ်။ ဒီလိုထည့်လိုက်တာ ကို အများစုက ဘာကြောင့်ထည့်တာလဲလို့ တွေးကြတယ်။ ဒီလိုထည့်လိုက်တဲ့အတွက် ဘယ်လောက်အထိ အကျိုးရှိသွားတယ်ဆိုတာကို မသိကြဘူး။ အောက်ကမြင့်တစ်ခုပဲ ရှိရမယ့် နေရာမှာ နှစ်ခုဖြစ်နေပြီး ထပ်နေမယ်ဆိုရင် ရှာချင်တဲ့ စာလုံး၊ စီချင်တဲ့အက္ခရာစဉ်ကို ဘယ်လိုမှ တွေ့နိုင်စီနိုင်မှာ မဟုတ်ဘူး။ Version 2 နဲ့ Version 3 ပေါ်မှာ ဘာကွာခြားချက်မှ မရှိဘူး။ အစက်ကလေးတွေပါတဲ့ စက်ဝိုင်းလေးတွေ ထပ်ထည့်လိုက်တာပဲ ရှိတယ်။ ဒီအပိုင်းကိုပဲ ကျွန်မပြောပြ နိုင်တယ်။ ပြင်တဲ့ အပိုင်းတွေ၊ Version 2 နဲ့ Version 3 ခွဲပြီး ထုတ်တဲ့အပိုင်းတွေကို Font Developing အပိုင်းက ဆောင်ရွက်ပါတယ်။
အပြောင်းအလဲတိုင်း အမှားကြောင့် မဟုတ်ဘူး
အလုပ်လုပ်နေတဲ့သူမှာ အမှားဆိုတာ ရှိနိုင်တယ်။ အလုပ်လုပ်နေတဲ့သူက မှားနိုင်တာပဲ။ အလုပ်ကို စမ်းတဝါးဝါးနဲ့ လုပ်တာမျိုး ရှိရင်ရှိမယ်။ မှန်တယ်ဆိုပြီး လုပ်လိုက်ပြီးမှ မထင်မှတ်တဲ့ ကိစ္စတစ်ခုက မှားသွားတာလဲ ဖြစ်ချင်ဖြစ်မယ်။ ယူနီကုတ်က Version တစ်ခုပြီး တစ်ခုထွက်လာ တယ်ဆိုတာ မှားလို့ ပြန်ပြင်တာ မဟုတ်ဘူးလို့ သိစေချင်တယ်။ သူတို့ဟာ တစ်ကမ္ဘာလုံးမှာရှိတဲ့ ဘာသာစကားတွေကို(ကွန်ပျူတာမှာ) အသုံးပြုနိုင်ဖို့ စံသတ်မှတ်ပေးတယ်။ တစ်ခြားနိုင်ငံတစ်ခုက ဘာသာစကားတစ်ခုမှာ လိုအပ်ချက် ရှိလာလို့ရှိရင်လည်း ထည့်သွင်းစဉ်းစား ပေးတယ်။ ယူနီကုတ်ဆိုတာ ဘာသာစကားတစ်ခုတည်းအတွက် မဟုတ်ဘူး။ ဘာသာစကားရှိမှ လူမျိုးရှိ မှာ။ ဘာသာစကားမှာ တစ်ခုခုမှား သွားလို့ ရှိရင် သက်ဆိုင်ရာ နိုင်ငံအတွက် ဆက်ပြီး မှားနေမယ်။ ပြောင်းလဲနေတိုင်းဟာ အမှားကြောင့်မဟုတ်ဘူး။ ဒါတွေနဲ့ ပတ်သက်ပြီး သိချင်ရင် ကျွန်မတို့ ဖြေရှင်းပေးဖို့ အဆင်သင့် ရှိပါတယ်။ ပြောင်းလဲတဲ့ နောက်ကွယ်မှာ တန်ဖိုးရှိတဲ့အရာတစ်ခု ရှိနေပါတယ်။ ယူနီကုတ် ၅.၁ ကို လိုက်နာထားတဲ့ ဖောင့်တွေအားလုံးဟာ အခုအချိန်မှာ မြန်မာစာအတွက် လုံးဝ တည်ငြိမ်သွားပြီလို့ ပြောလို့ရတယ်။
နည်းပညာပိုင်းကနေ ဖြေရှင်းပေးရမယ်
အေအကြီး(A)ကို ဂျာမန်တွေက အေ(A) အသံမထွက်ဘူး။ သူတို့သုံးထားတဲ့ Charater က အင်္ဂလိပ်ရဲ့ Charater ဖြစ်နေတယ်။ သူတို့က အေ အကြီး(A)ကို အသံတစ်သံထွက်ပြီး တစ်နေရာမှာ အသုံးပြုပေမယ့် အေအသေး(a)က အင်္ဂလိပ်မှာ မူရင်းအတိုင်းပဲ ရှိချင်ရှိနေမယ်။ အေအကြီး(A)မို့လို့ အသံပြောင်း၊ အဓိပ္ပါယ်ပြောင်းနိုင်ပေမယ့် အဲဒီအပေါ်မှာ မမီခိုဘူး။ ဂျာမန်အတွက်ဆိုပြီး အေအကြီး(A) သက်သက် မရှိဘူး။ အင်္ဂလိပ်အတွက်ဆိုပြီး အေအကြီး(A) သက်သက်မရှိဘူး။ မမီခိုဘူးဆိုတာ ဒီလိုသဘောမျိုးကို ပြောလိုက်တာပဲ။ အေအကြီး (A)ပြီးရင် အေအသေး(a)လာရမယ်ဆိုတဲ့ ဘာသာစကားရဲ့ သဘာဝတော့ ရှိတယ်။ မြန်မာစာမှာလည်း ရေးချ၊ မောက်ချနှစ်ခုဟာ Level တူ တယ်။ Sorting လုပ်ရင် ရေးချသော်လည်းကောင်း မောက်ချသော်လည်းကောင်း အပေါ်ရောက်နေလိမ့်မယ်။ သူတို့နှစ်ခုကြားမှာ ဘယ်ဟာမှ ဝင်လို့ မရဘူး။ ကုတ်တွေ တစ်ခုက တစ်မျိုး တစ်ခုက တစ်မျိုးလည်း မဟုတ်ဘူး။ ရေးချဟာ မြန်မာစာအတွက်ဖြစ်ပြီး မောက်ချဟာ စကော ကရင်မှာသုံးတဲ့ ဘာသာစကားရဲ့သဘာဝ ဖြစ်နေတယ်။ ရေးချချည်းပဲ ရှာချင်တယ်။ မောက်ချချည်းပဲ ရှာချင်ပါတယ်ဆိုရင် Fine and Replace မှာ သုံးတဲ့ Match Case နဲ့ရှာမလား။ Default နဲ့ ရှာမလား ဆိုတာကို Technical အပိုင်းကနေ ဖြေရှင်းပေးရတယ်။ ဘာသာစကားရဲ့ သဘာဝ ကနေ ဖြေရှင်းပေးလို့ မရဘူး။
စံသတ်မှတ်ချက်ကို အတိအကျ လိုက်နာကြတယ်
ယူနီကုတ်နဲ့ပတ်သက်လာရင် တစ်ခြားနိုင်ငံတွေမှာ ဝေဖန်ကြတယ်ဆိုတဲ့ ဝေဖန်ချက်တွေကို မကြားရဘူး။ နိုင်ငံတကာ စံနှုန်းသတ်မှတ်ချက် က ချမှတ်ပေးလိုက်တဲ့ စံသတ်မှတ်ချက်တစ်ခုကိုပဲ သူတို့က သုံးလိုက်ကြတယ်။ ပြည်တွင်းမှာ မြန်မာယူနီကုတ်နဲ့ ပတ်သက်ပြီး အငြင်းပွား ကြတယ်လို့ ပြောရင် သူတို့ မသိဘူး။ သူတို့အတွက်က ပြောစရာကိစ္စတစ်ခု မဟုတ်ဘူး။ စံနှုန်းသတ်မှတ်ချက်တစ်ခု ထွက်ပေါ်လာရင် အတိအကျလိုက်နာပြီးသား ဖြစ်နေတယ်။ သူတို့ထုတ်တဲ့ ဆော့်ဝဲလ်တွေကို စံနှုန်းမီချင်တဲ့အတွက် သူတို့လည်း စံနှုန်းသတ်မှတ်ချက်နဲ့ ကိုက်ညီတာကိုပဲ သုံးတယ်။ သူတို့မိခင်ဘာသာစကားနဲ့ထုတ်တဲ့ အိုင်စီတီထုတ်ကုန်တွေကို စံနှုန်းကိုက်တဲ့ ယူနီကုတ်နဲ့ပဲ ထုတ်လုပ်တယ်။
ကကြီး သဝေထိုး၊ သဝေထိုး ကကြီး
ကကြီး သဝေထိုးလို့ သွားပြီးတော့ သိမ်းဆည်းပေးတာက ယူနီကုတ်မဟုတ်ဘူး။ ဘာသာစကားရဲ့ သဘာဝတစ်ခုပဲဖြစ်တယ်။ ဒီလို သိမ်းပေး ရတဲ့အကြောင်းအရင်းရဲ့ အနီးစပ်ဆုံးအကြောင်းအရာက Sorting အတွက်ပဲ။ Sorting မှာ ဗျည်းက အရင်စပြီးတော့ လာတယ်။ ပြီးရင် သရစဉ် လာတယ်။ အက္ခရာစဉ်လာတယ်။ ဒီလိုသွားတဲ့ ပုံစံဟာ မြန်မာဘာသာစကားရဲ့ သဘာဝပဲ။ ဒီအတိုင်းကိုပဲ လိုက်ပြီးတော့ သိမ်းတာပဲ။ သိမ်း တဲ့ နေရာမှာ Sorting ထက်မကတဲ့အပိုင်းတွေ အများကြီးရှိသေးတယ်။ Sorting လုပ်ပြီဆိုကတည်းက အကြီးဆုံး အသေးဆုံးဆိုပြီး Ascending, Dscending တွေကို စဉ်းစာကြတာလေ။ ဒါကို စဉ်းစားလိုက်တယ်ဆိုတာနဲ့ ကကြီးသဝေထိုး သိမ်းသင့်သလား။ သဝေထိုးကကြီး သိမ်းသင့် သလားဆိုတဲ့အချက်က ပေါ်လာပါတယ်။
စံနှုန်းတစ်ခုကို မလိုက်နာတဲ့ အခါ
မြန်မာသင်္ချာဂဏန်းတွေနဲ့ ပေါင်းနုတ်မြှောက်စားလုပ်လို့ မရသေးဘူးဆိုတာက ယူနီကုတ်ကြောင့် မဟုတ်ဘူး။ ဘာသာ စကားသဘာဝ ကြောင့်လည်း မဟုတ်ပြန်ဘူး။ အရှင်းဆုံးပြောလိုက်ရင် OS မှာ မြန်မာစာ မရှိသေးလို့ပဲ။ Microsoft Windows မှာ မြန်မာစာမရှိသေးတဲ့အတွက် မြန်မာစာကို သိအောင်လုပ်ပေးနေရတယ်။ အခု Mac ပေါ်မှာ မြန်မာစာကို Mac OS ကသိနေတဲ့အတွက် မြန်မာသင်္ချာဂဏန်းနဲ့ ပေါင်းနုတ် မြောက်စား လုပ်နိုင်နေပါတယ်။ ယူနီကုတ်စံမမီတဲ့တစ်ခုကို ဆက်ပြီးသုံးနေမယ်ဆိုရင် Windows မှာ မြန်မာစာကို သိအောင်တစ်ခါတည်း လုပ်ပေးထားတဲ့ အခြေအနေရောက်လာတဲ့အခါ လက်ရှိလုပ်ထားခဲ့တဲ့ အလုပ်တွေအတွက် ဆုံးရှုံးမှုတွေ ဖြစ်လာနိုင်တယ်။ ယူနီကုတ် စံမမီတဲ့တစ်ခုကို ဆက်ပြီးသုံးနေလို့ ရနေတယ်ဆိုပေမယ့် နိုင် ငံတကာမှာ စံသတ်မှတ်ချက်တစ်ခုကိုပဲ အတိအကျလိုက်နာကြတဲ့အတွက် ကိုယ့်အနေနဲ့က ကွက်ပြီး ကျန်ခဲ့လိမ့်မယ်။ ယူနီကုတ်ကွန်ဆိုဒီယမ်က ချမှတ်လိုက်တဲ့ စံသတ်မှတ်ချက်ကို လိုက်နာခဲ့တယ်ဆိုရင် ထုတ်တဲ့ ဆော့်ဝဲလ်တွေ အားလုံးဟာ နိုင်ငံတကာစံနှုန်းထဲကို ဝင်နိုင်တဲ့ အချက်တစ်ချက်ဖြစ်သွားတယ်။
လေ့လာ၊ ဆွေးနွေး၊ အကြံပေး
ယူနီကုတ်အကြောင်းကို အသေးစိတ်သိချင်တယ်ဆိုရင် www.unicode.org မှာ ဖတ်ကြည့်တာ အကောင်းဆုံးပဲ။ www. myanmarnlp.net.mm မှာ လည်း ဖတ်ကြည့်လို့ရတယ်။ MM NLP ရဲ့ သုတေသနရလာဒ်တွေကို ပြန်လည်မျှဝေဖို့ ဝက်ဘ်ဆိုဒ်အသစ်တစ်ခုကိုလည်း စီစဉ်နေတယ်။ ဒီထက်ပိုပြီးတော့ သိချင်တယ်ဆိုရင် MMNLP အနေနဲ့ အဆင်သင့်ရှိပါတယ်။ ဆက်သွယ်နိုင်ပါတယ်။ နားထောင်ရုံ သက်သက်ထက် ဆွေးနွေးပေးတာကို ပိုပြီး လိုချင်ပါတယ်။ ပြန်လည်ဆွေးနွေး အကြံပေးတာကို လိုချင်ပါတယ်။ ချက်ခြင်းသိချင်တဲ့ ကိစ္စမျိုးဆိုရင် ဖုန်းဆက်ပြီးတော့လည်း မေးနိုင်ပါတယ်။ ဒီလိုမျိုးတွေကို ဖွင့်ပေးထားပေမယ့် မလာကြပါဘူး။
ဆွေးနွေးမှု၊ အဖြေ၊ အကျိုးကျေးဇူး
ကိုယ်နဲ့ မဆိုင်ဘူးဆိုရင် သုံးလည်း မသုံးနဲ့ ဝေဖန်မှုလည်း မလုပ်ပါနဲ့။ သိတယ်ဆိုရင်တော့ ဝေဖန်လို့ရတယ်။ သိတဲ့အတိုင်းကို ဝေဖန်ပါ။ ဝေဖန်တာပဲ ဖြစ်ဖြစ်၊ အကြံပေးတာပဲ ဖြစ်ဖြစ်၊ နားထောင်တာပဲ ဖြစ်ဖြစ်၊ ဆွေးနွေးတာပဲ ဖြစ်ဖြစ် နည်းနည်းလေးသိရင် သိတဲ့အပေါ်မှာ အခြေခံပြီး မေးလို့ရတယ်။ လုံးဝမသိပဲနဲ့ ဘေးကပြောတဲ့ စကားနဲ့လိုက်ပြီး ပြောတာမျိုးတော့ မဖြစ်စေချင်ဘူး။ ယူနီကုတ်ကို ဘာလို့ ကြီးကြီးကျယ်ကျယ် ပြောနေတာလဲ၊ ဘာလို့အချိန်ကုန်ခံနေတာလဲလို့ သိချင်လာပြီဆိုရင် သိချင်တဲ့ အသိအပေါ်မှာ ထပ်ပြီးတော့ ကြိုးစားဖို့ လိုအပ်ပါတယ်။ ယူနီကုတ်နဲ့ ပတ်သက်ပြီး ဝက်ဘ်ဆိုဒ်တစ်ချို့မှာ ငြင်းခုန် ဆွေးနွေးကြတာကို တွေ့ရတယ်။ ပြောတဲ့သူကလည်း ပြောတယ်။ ဖြေရှင်းပေးတဲ့ သူကလည်း ဖြေရှင်းတယ်။ ဒါပေမယ့် အခုအချိန်အထိ အဖြေတစ်ခု မရကြသေးဘူး။ ဆွေးနွေးမှုဆိုတာ အဖြေတစ်ခုရသွားမှ အောင်မြင်တာပါ။ အဖြေတစ်ခုမရသေးဘူးဆိုရင် ဆွေးနွေးမှုတွေဟာ အကျိုးမရှိပါဘူး။
ပီပီပြင်ပြင် အသုံးပြုနေတဲ့ အချိန်မှာ
အကျိုးကျေးဇူးက ပြောရမယ်ဆိုရင် အများကြီးပဲ။ အခု မိုက်ခရိုဆော့ဝ်လ်မှာ မြန်မာစာရိုက်နေရတာ Line Brake မရှိဘူး။ Word Break မရှိဘူး။ Phrase Brake မရှိဘူး။ စာရိုက်ရင် တကယ်တမ်းရိုက်နေတာက Phrase Brake နဲ့ ရိုက်နေတာ။ မောင်မောင်သည်ဆိုရင် သည်မှာ ဖြတ်ပေးနေရ တယ်။ ဒါမျိုးတွေရဖို့အတွက် အများကြီးကို ကြိုးစားနေရတယ်။ မြန်မာစာမှာ Phrase ဆိုတာဘယ်နေရာလဲလို့ မြန်မာစာဆရာကြီးတွေနဲ့ တိုင်ပင်ရတယ်။ ပြီးတော့မှာ တကယ်အသုံးချတဲ့အပေါ်မှာရေး ရတယ်။ မြန်မာဘာသာစကားမှာ တစ်ခြားဘာသာစကားနဲ့မတူညီတဲ့ အချက် တွေရှိတယ်။ မြန်မာဘာသာစကားမှာ ဒါတွေ့ရင် ဒါလုပ်ဆိုတဲ့ ပုံစံမရှိဘူး။ ဒါလည်းဖြစ်နိုင်တယ်။ ဟိုတစ်ခုလည်း ဖြစ်နိုင်တယ်ဆိုတဲ့ ပုံစံမျိုးရှိ တယ်။ ဖြစ်နိုင်တွေချေကို အခြေခံပြီးတော့ တွက်ချက်ရတယ်။ ဒီလိုအခြေအနေမျိုးမှာ အလုပ်လုပ်ရတဲ့အတွက် တစ်ချို့ကိစ္စတွေမှာ အရမ်းကို ခက်ခဲတယ်။ ဒီလို အချိန်အကုန်ခံပြီး ရှင်းခဲ့ရတဲ့ ပြဿနာတွေက ယူနီကုတ်ကို ပီပီပြင်ပြင်သုံးနေရတဲ့ အချိန်မှာ အားလုံးပြေလည်နေပြီ။ ကျွန်မတို့ ခက်ခက်ခဲခဲလုပ်ခဲ့ရပါတယ်လို့ အဲဒီအချိန်မှာ ပြောရင် ဘယ်သူမှ ယုံကြတော့မှာမဟုတ်ဘူး။
ဘာသာစကား၊ နည်းပညာ
မိခင်ဘာသာစကားနဲ့ ပတ်သက်ပြီး ၅ နှစ်ကျော်လောက် လုပ်လာရပေမယ့် အခုအချိန်အထိ လေ့လာနေရတုန်းပဲ။ ကိုယ်မသိတဲ့အရာတွေက အများကြီးပဲ။ အင်တိုက်အားတိုက်နဲ့ လုပ်နေကြတဲ့အထဲမှာ မြန်မာက နောက်မကျပါဘူး။ လိုက်နိုင်ပါတယ်။ သူတို့ထက် ကြိုမြင်ခဲ့တဲ့ အပိုင်း တွေလည်း ရှိတယ်။ တစ်ချို့အပိုင်းတွေမှာ မြန်မာဆိုတဲ့ဘာသာစကားကို ဘယ်သူမှ မသိကြဘူး။ ကိုယ့်အနေနဲ့က ကမ္ဘောဒီးယားကိုလည်း သိတယ်။ ဗီယက်နမ်ဘယ်လို ရှိသလဲဆိုတာကို လေ့လာတယ်။ ထိုင်းက ဘယ်လိုရှိသလဲ၊ ဂျပန်က ဘယ်လိုရှိသလဲ ဆိုတာတွေကို သိနေတယ်။ ဒီလိုသိနေတာက အားသာချက်တစ်ခုပဲ။ သူတို့ ဘာသာစကားနဲ့ ကိုယ့်ရဲ့ ဘာသာစကားမှာ ဘယ်အပိုင်းတွေ တူနေတယ်ဆိုတာ သိထားတဲ့ အတွက် ကိုယ့်အနေနဲ့ သူတို့ဆီက ဘာယူသုံးလို့ ရမလဲဆိုတာ သိတယ်။ ဒီလိုအတွေ့အကြုံမျိုးတွေ ရတယ်။ သူတို့ဆီမှာ NLP နဲ့ ပတ်သက်ပြီး အင်တိုက်အားတိုက်ကို လုပ်ကြတယ်။ NLP ကို တစ်ဦးတစ်ယောက်တည်း လုပ်လို့မရဘူး။ အားလုံး စုပေါင်းပြီးတော့ လုပ်ရတယ်။ စုပေါင်း လုပ်ကိုင်တဲ့အပိုင်းမှာ မြန်မာက အားနည်းတယ်။ ကျန်တဲ့အပိုင်းတွေမှာတော့ လိုက်နိုင်တယ်။ Myanmar NLP Lab မှာ အစပိုင်း စလုပ်တုန်းက ယူနီကုတ် စံသတ်မှတ်ချက်ဖြစ်အောင်၊ မြန်မာနိုင်ငံမှာ ယူနီကုတ်အသုံးပြုနိုင်အောင်ဆိုတဲ့ အပိုင်းတွေ ပိုများတယ်။ နှစ်နှစ်လောက် အလုပ် လုပ်ပြီးတဲ့အခါမှာ ယူနီကုတ်ရဲ့ Enconding ပေါ်မှာ ဘာတွေ လုပ်ကြမလဲဆိုတဲ့ အပိုင်းတွေ ရှိလာတယ်။ သဒ္ဒါနည်းနဲ့ တည်ဆောက်ရတဲ့ အပိုင်းတွေ ပါလာတယ်။ ဒီလိုပါလာတော့ ဘာသာဗေဒကျွမ်းကျင်သူတွေလည်း ပါလာရတယ်။ ဘာသာဗေဒကျွမ်းကျင်သူ ပညာရှင်တွေရဲ့ အကြံဉာ ဏ်တွေကို အများဆုံးယူတယ်။ သုတေသနလည်း လုပ်တယ်။ ဘာသာစကားသဘာဝနဲ့ နည်းပညာပေါင်းစပ်လို့ရတဲ့ အခြေအနေ အထိရောက်အောင် ပညာရှင်တွေနဲ့ တိုင်ပင်ပြီးတော့ လုပ်ကိုင်ဆောင်ရွက်တယ်။
ဘာသာစကားအရင်းအမြစ် လိုအပ်ချက်
ဘာသာစကားနဲ့ပတ်သက်ပြီး ဂဃနဏ မသိခင်မှာ နည်းပညာနောက်ကို လိုက်ခဲ့ရတယ်။ ပြည်ပမှာ သင်တန်းတစ်ချို့ကို တက်ခွင့်ရတော့ မြန်မာက NLP အနေနဲ့ နောက်ကျနေတယ်ဆိုတာကို တွေ့ရတယ်။ ဒီလိုနောက်ကျတဲ့အတွက် ကံကောင်းသွားတယ်လို့ ပြောနိုင်တယ်။ သူတို့ က(နည်းပညာကို) ရှာပြီးသား ကိုယ်က ယူသုံးရုံပဲ။ ဘာကို ယူသုံးရမလဲဆိုတာကို အများစုက အသိကြဘူး။ စာလုံးပေါင်းစစ်ဆေးဖို့ဆိုရင် အဘိဓာန်ကောင်းကောင်းလိုမယ်။ မရှိဘူး။ ဘာသာစကားနဲ့ပတ်သက်ပြီး စုဆောင်းထားတာတွေ မရှိဘူး။ မြန်မာဘာသာစကားမှာ Word, Phrase ဆိုတာ ဒါတွေပဲလို့ ပေးလိုက်တာနဲ့ ဒီအပေါ်မှာ Word Break တွေ၊ Phrase တွေ ရနေနိုင်ပြီ။ အဘိဓာန်တစ်ခုပေးလိုက်တာနဲ့ မြန်မာစာ လုံး ပေါင်းစစ်ဖို့ အဆင်ပြေသွားမယ်။ နည်းပညာအပိုင်းကနေ ကျွန်မတို့လုပ်ပေးနိုင်က နှစ်ဆယ်ရာခိုင်နှုန်းလောက်ပဲရှိတယ်။ ကျန်တဲ့ ရှစ်ဆယ်ရာခိုင်နှုန်းက ဘာသာစကားကျွမ်းကျင်သူတွေ၊ အရင်းအမြစ်တွေကို ထိန်းသိမ်းရတဲ့သူတွေ၊ အချက်အလက်တွေကို ထိန်းသိမ်းမယ့် သူတွေဆီက ဘာသာစကားဆိုင်ရာ အရင်းအမြစ်တွေပဲ။ နည်းပညာက ကျွန်မတို့မှာ အဆင်သင့်ရှိနေတယ်။ ကျွန်မတို့အတွက် လိုအပ်နေတာ က အရင်းအမြစ်ပဲ။ ဘာသာစကားအရင်းအမြစ်က MMNLP တိုးတက်ဖို့ အကောင်းဆုံးလိုအပ်ချက်ပဲ။
သိလိုသမျှကို စိတ်ရှည်စွာ အချိန်ပေး ဖြေကြားပေးခဲ့တဲ့ မသင်ဇာဖြိုးကို ကျေးဇူးတင် မှတ်တမ်းထားပါတယ်။
ဟန်ဇော်
၂၀၁၁ ခုနှစ်၊ ဇန်နဝါရီလထုတ် ပါစင်နယ်ကွန်ပျူတာမဂ္ဂဇင်းတွင် ဖော်ပြခဲ့ပါသည်။


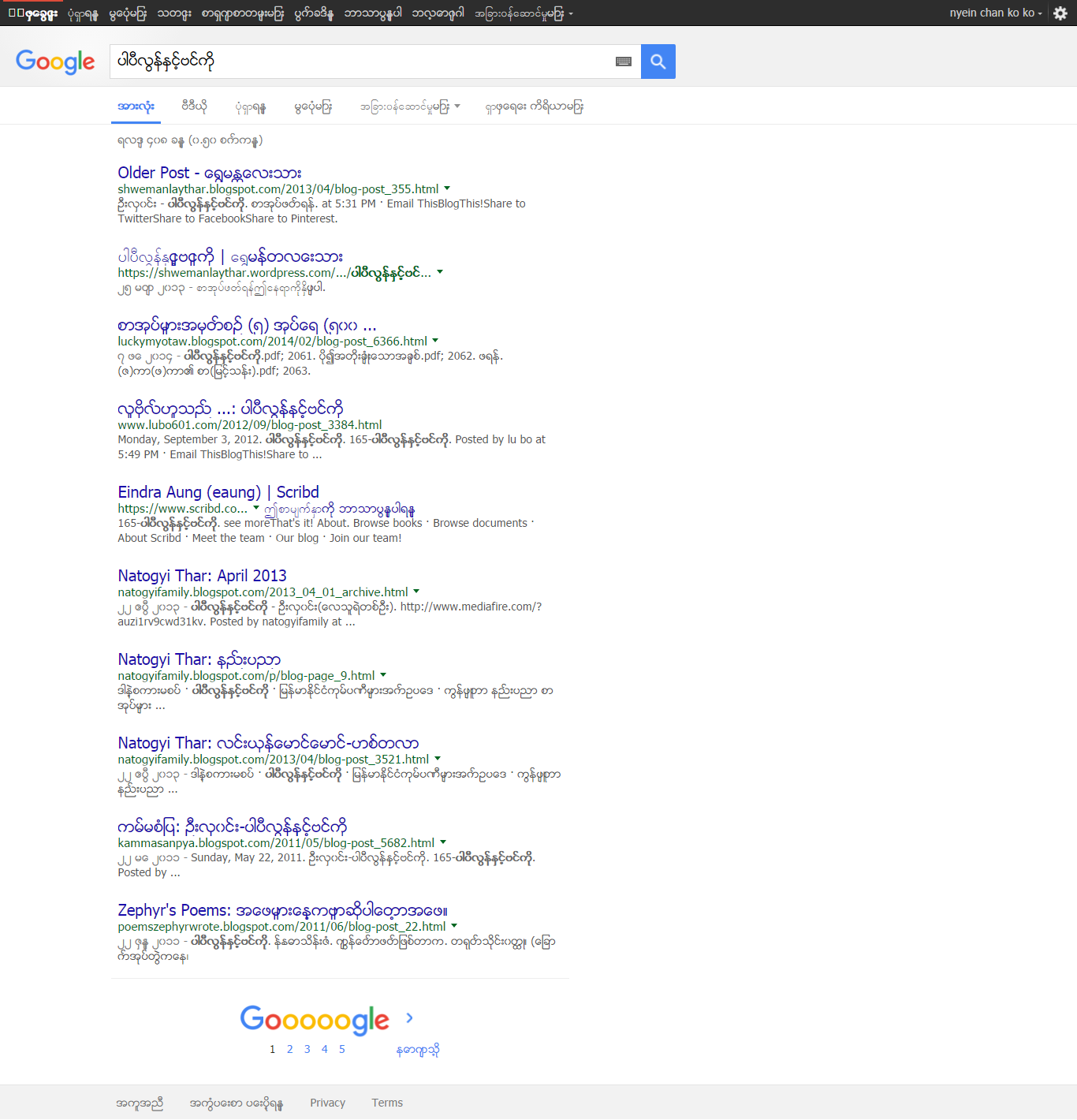
 ပုံ(၁) ယူနီကုဒ်ဖြင့်ရှာဖွေခြင်း
ပုံ(၁) ယူနီကုဒ်ဖြင့်ရှာဖွေခြင်း
 Camera ကို Scanner အဖြစ်အသုံးပြုတဲ့အခါမှာ
Camera ကို Scanner အဖြစ်အသုံးပြုတဲ့အခါမှာ